The development impact community has made tremendous progress in promoting evidence use for policymaking and establishing rigorous standards for quantitative estimation of important intervention effects (e.g., in schooling, health, and sanitation). The average treatment effect (ATE) generated from an impact evaluation is instrumental in measuring the impact of a program on participants. But how can we go beyond the average effect to understand how an intervention uniquely impacts each participant in the study? At 3ie, we recently tested a machine learning technique on a previously completed randomized controlled trial (RCT) of a school-based gender attitude change program in Haryana, India to answer this question. We share a few key findings and benefits of employing this method.
Understanding and addressing intersectionality
Due to methodological limitations (among other reasons), program designs have overlooked various intersecting aspects of a person’s identity, background, and environment that influence how an intervention may affect their outcomes. However, understanding and accounting for this intersectionality is paramount, especially when individuals are marginalized because of it and may need targeted policies to enable their advancement. The pursuit to go beyond the ATE comes at a time when computing and machine learning (ML) methods are more accessible to us than ever before. Academic researchers have discovered useful ways to leverage these novel ML methods to estimate “treatment effect heterogeneity” i.e., quantifying whether and how an intervention impacted various participants differently. Commonly used approaches for exploring these differences, such as sub-group analysis or adding additional terms to linear regression, are effective when limited to a few pre-selected characteristics (e.g., gender, geography) that are theorized to be relevant. Adding too many terms or splitting the sample on multiple characteristics can take a long time and/or would require a sizeable (and often infeasible) amount of data.
A machine learning technique – Causal forest (CF) analysis – offers a way to measure differences granularly, so we can examine the intervention’s effect through an intersectional lens. This technique, developed by Stefan Wager and Susan Athey, uses an ensemble of decision trees (i.e., a random forest) to model heterogeneity and estimate a treatment effect, known as the Conditional ATE or CATE, for each study participant. It lets the data drive the creation of the most heterogeneous sub-groups by testing all possible interactions of characteristics.
Uncovering additional insights using CF
The original study examined heterogeneity by gender and parental attitudes using interaction terms and found no differential impact on gender attitudes. Applying the causal forest method, we uncover further heterogeneity in impact, including other, perhaps unexpected characteristics, such as sibling age. One key benefit of this method is that we didn’t have to narrowly pre-define the expected drivers of heterogeneity, especially the interaction terms. For example, we find that students more likely to have a TV in the house, younger siblings, younger and less educated parents, more household assets, and lower desired educational qualifications, self-efficacy, and aspirations, are impacted more, without us having to pre-specify such a sub-group. Relatedly, we didn’t have to pre-specify a linear relationship between these sub-groups and the outcome, thereby allowing the model to find a good (potentially non-linear) fit.
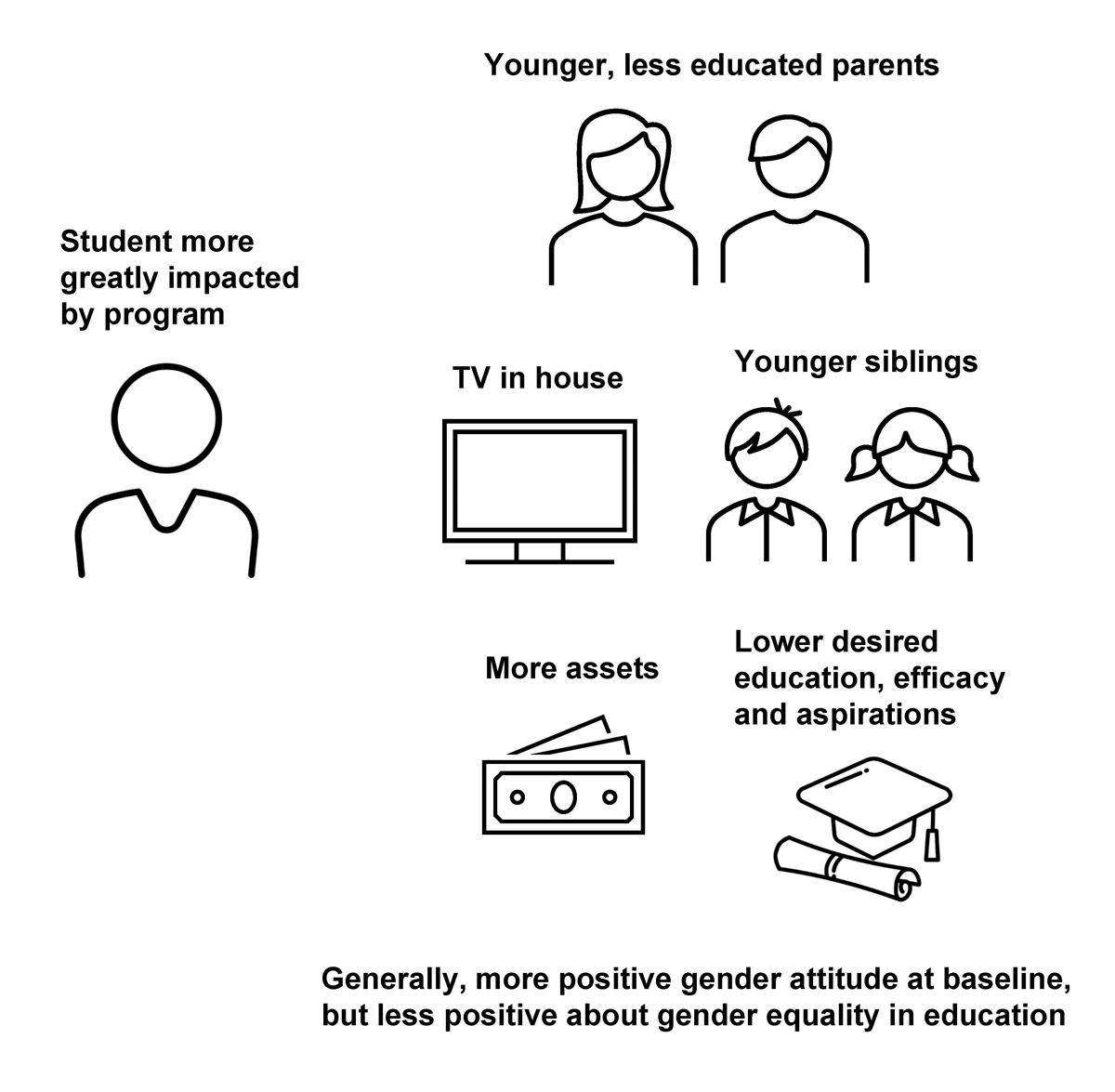
We can also see how and to what extent those characteristics vary for those more impacted versus less impacted by the program. For example, of those students most impacted by the program (quartile 4 of CATEs), 91% have a TV in their home, which is significantly different from the 76.7% that have a TV in the group of least impacted students (quartile 1 of CATEs).
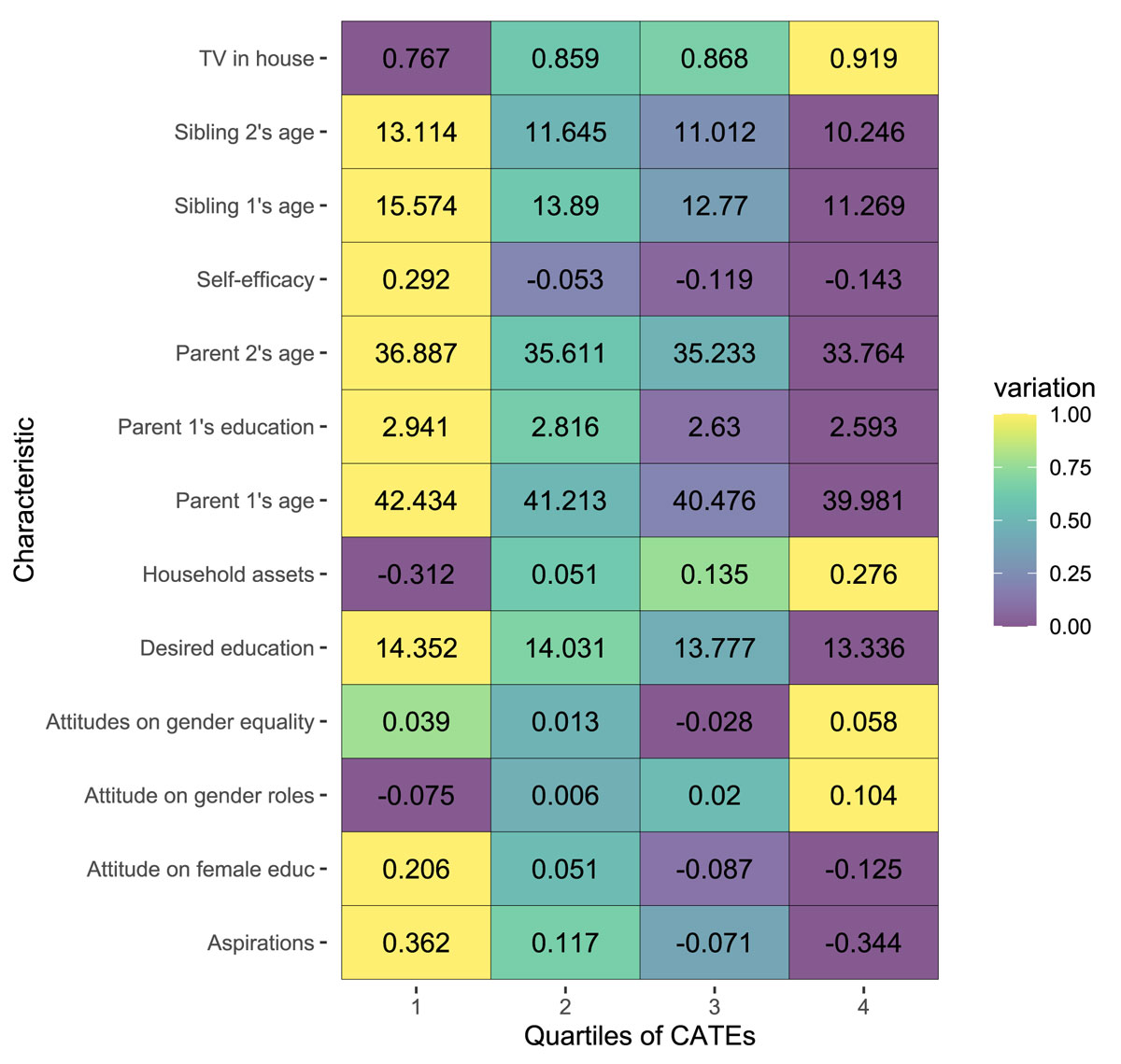
Ultimately, the model independently takes the decision of which characteristics to include and which functional form to use, with little input from the researcher. This can prevent several ad-hoc attempts to find differences (a form of “data mining”), keep the focus on transparent analysis, and save valuable time.
Addressing resource constraints: leveraging CFs for targeting
Furthermore, the results from the CF model can be used by policymakers to target sub-groups most likely to benefit from the program, without having to run another experiment. For example, if the Breakthrough study were to be rolled out in another state in India, government officials could feed baseline data from this state into our pre-trained CF model and estimate CATEs for each student in the new sample. Identifying the sub-group with the highest CATE can increase program effectiveness by first targeting those most likely to experience larger impacts of the intervention. Suppose the results for this new state showed that male students who had a female role model in their immediate environment, lived in urban areas, and belonged to a minority caste, had the highest CATE, then targeting this group as the first recipients of gender attitudes training sessions could help fortify the impact of the intervention.
Going beyond quantitative data: applying a qualitative lens
Qualitative methods integrated into the evaluation design could help strengthen the causal forest method. For our experiment, we applied an intersectional lens (in the absence of qualitative data) to hypothesize on why owning a TV or having less educated parents might affect the gender attitudes of the students in our high-impact sub-group. The nature of TV programming that an adolescent is exposed to could affect the way in which they perceive gender norms. Content perpetuating traditional gender norms would hence impact students’ attitudes. Similarly, parents’ educational achievements could influence female students’ career aspirations. Understanding these latent contextual factors is crucial for policy-level decisions. Using these nuanced insights, policymakers could tailor programs to meet specific populations’ needs. This would save valuable time and resources in policymaking.
More guidance for wider applicability
Despite the causal forest method being demonstrably powerful and efficient, the process of applying this method has highlighted a need for further clarification and exploration, especially from the point of view of evaluators and policymakers. Existing resources on this topic, albeit extensive and detailed, are difficult to parse for a non-academic audience. Complicated outputs of the machine learning model are often hard to explain and interpret. This may deter policymakers and those not well-versed in ML methods from adopting proposals for applying this method to their interventions. Through our testing, we attempt to illustrate how one can simplify information from the model into insights that are understandable to a general audience. To make this methodology even more accessible to a variety of audiences, we need further effort to create guidance materials emphasizing this method’s wide applicability.
As a field, we must prioritize mixed-method approaches to impact evaluations, where a novel methodology like CF is paired with qualitative insights to enrich evidence generation for policymaking. If you are interested in learning more about this application of causal forests, sharing your experience applying this method, or partnering on similar projects in the future, reach out to info@3ieimpact.org.








